RDMA-RoCEv2 ibv_reg_mr 分析
1. 用户程序调用 IBVerbs
用户调用的ibv_reg_mr中包含四个参数,如下所示
1
2struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd, void *addr,
size_t length, enum ibv_access_flags acceshttps://www.rdmamojo.com/2012/09/07/ibv_reg_mr/
Name Direction Description pd in Protection Domain that was returned from ibv_alloc_pd() addr in The start address of the virtual contiguous memory block length in Size of the memory block to register, in bytes. This value must be at least 1 and less than dev_cap.max_mr_size access in Requested access permissions for the memory region 在当前的rdma-core实现下,会实际调用ibv_reg_mr_iova2,传入的addr/iova两个参数相等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// rdma-core/libibverbs/verbs.c
#undef ibv_reg_mr
LATEST_SYMVER_FUNC(ibv_reg_mr, 1_1, "IBVERBS_1.1",
struct ibv_mr *,
struct ibv_pd *pd, void *addr,
size_t length, int access)
{
return ibv_reg_mr_iova2(pd, addr, length, (uintptr_t)addr, access);
}
struct ibv_mr *ibv_reg_mr_iova2(struct ibv_pd *pd, void *addr, size_t length,
uint64_t iova, unsigned int access)
{
struct verbs_device *device = verbs_get_device(pd->context->device);
bool odp_mr = access & IBV_ACCESS_ON_DEMAND;
struct ibv_mr *mr;
if (!(device->core_support & IB_UVERBS_CORE_SUPPORT_OPTIONAL_MR_ACCESS))
access &= ~IBV_ACCESS_OPTIONAL_RANGE;
if (!odp_mr && ibv_dontfork_range(addr, length))
return NULL;
mr = get_ops(pd->context)->reg_mr(pd, addr, length, iova, access);
if (mr) {
mr->context = pd->context;
mr->pd = pd;
mr->addr = addr;
mr->length = length;
} else {
if (!odp_mr)
ibv_dofork_range(addr, length);
}
return mr;
}
2. 用户态libRXE
libRXE中,rxe_reg_mr 函数指针注册为
ops->reg_mr1
2
3
4
5
6
7
8
9
10// rdma-core/providers/rxe/rxe.c
static const struct verbs_context_ops rxe_ctx_ops = {
...
.reg_mr = rxe_reg_mr,
.dereg_mr = rxe_dereg_mr,
.alloc_mw = rxe_alloc_mw,
.dealloc_mw = rxe_dealloc_mw,
.bind_mw = rxe_bind_mw,
...
};rxe_reg_mr 实现
- 申请一个verbs_mr结构体空间
- 通过ibv_cmd_reg_mr执行系统调用。注意这里 addr 和 hca_va 参数是相等的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// rdma-core/providers/rxe/rxe.c
static struct ibv_mr *rxe_reg_mr(struct ibv_pd *pd, void *addr, size_t length,
uint64_t hca_va, int access)
{
struct verbs_mr *vmr;
struct ibv_reg_mr cmd;
struct ib_uverbs_reg_mr_resp resp;
int ret;
vmr = calloc(1, sizeof(*vmr));
if (!vmr)
return NULL;
ret = ibv_cmd_reg_mr(pd, addr, length, hca_va, access, vmr, &cmd,
sizeof(cmd), &resp, sizeof(resp));
if (ret) {
free(vmr);
return NULL;
}
return &vmr->ibv_mr;
}
3. 发起write系统调用
- ibv_cmd_reg_mr 实现
- 将传入参数写入到cmd结构体中
- 发起write系统调用, 发起的cmd名称为 IB_USER_VERBS_CMD_REG_MR
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// rdma-core/libibverbs/cmd.c
int ibv_cmd_reg_mr(struct ibv_pd *pd, void *addr, size_t length,
uint64_t hca_va, int access,
struct verbs_mr *vmr, struct ibv_reg_mr *cmd,
size_t cmd_size,
struct ib_uverbs_reg_mr_resp *resp, size_t resp_size)
{
int ret;
cmd->start = (uintptr_t) addr;
cmd->length = length;
/* On demand access and entire address space means implicit.
* In that case set the value in the command to what kernel expects.
*/
if (access & IBV_ACCESS_ON_DEMAND) {
if (length == SIZE_MAX && addr) {
errno = EINVAL;
return EINVAL;
}
if (length == SIZE_MAX)
cmd->length = UINT64_MAX;
}
cmd->hca_va = hca_va;
cmd->pd_handle = pd->handle;
cmd->access_flags = access;
ret = execute_cmd_write(pd->context, IB_USER_VERBS_CMD_REG_MR, cmd,
cmd_size, resp, resp_size);
if (ret)
return ret;
vmr->ibv_mr.handle = resp->mr_handle;
vmr->ibv_mr.lkey = resp->lkey;
vmr->ibv_mr.rkey = resp->rkey;
vmr->ibv_mr.context = pd->context;
vmr->mr_type = IBV_MR_TYPE_MR;
vmr->access = access;
return 0;
}- 这里补充下 ib_uverbs_reg_mr 系统调用传入的结构体,以及 ib_uverbs_reg_mr_resp 传回结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct ib_uverbs_reg_mr {
__aligned_u64 response;
__aligned_u64 start;
__aligned_u64 length;
__aligned_u64 hca_va;
__u32 pd_handle;
__u32 access_flags;
__aligned_u64 driver_data[0];
};
struct ib_uverbs_reg_mr_resp {
__u32 mr_handle;
__u32 lkey;
__u32 rkey;
__u32 driver_data[0];
};
4. 内核中rdma-core处理系统调用
IB_USER_VERBS_CMD_REG_MR 方法的write系统调用,由 ib_uverbs_reg_mr 函数处理
1
2
3
4
5
6
7// kernel/drivers/infiniband/core/uverbs_cmd.c
DECLARE_UVERBS_WRITE(
IB_USER_VERBS_CMD_REG_MR,
ib_uverbs_reg_mr,
UAPI_DEF_WRITE_UDATA_IO(struct ib_uverbs_reg_mr,
struct ib_uverbs_reg_mr_resp),
UAPI_DEF_METHOD_NEEDS_FN(reg_user_mr)),ib_uverbs_reg_mr 实现
- 取出传入的ib_uverbs_reg_mr结构体,这里检查 cmd.start 和 cmd.hca_va 两个地址是否相等
- 执行实际的 reg_user_mr 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68// kernel/drivers/infiniband/core/uverbs_cmd.c
static int ib_uverbs_reg_mr(struct uverbs_attr_bundle *attrs)
{
struct ib_uverbs_reg_mr_resp resp = {};
struct ib_uverbs_reg_mr cmd;
struct ib_uobject *uobj;
struct ib_pd *pd;
struct ib_mr *mr;
int ret;
struct ib_device *ib_dev;
ret = uverbs_request(attrs, &cmd, sizeof(cmd));
if (ret)
return ret;
if ((cmd.start & ~PAGE_MASK) != (cmd.hca_va & ~PAGE_MASK))
return -EINVAL;
uobj = uobj_alloc(UVERBS_OBJECT_MR, attrs, &ib_dev);
if (IS_ERR(uobj))
return PTR_ERR(uobj);
ret = ib_check_mr_access(ib_dev, cmd.access_flags);
if (ret)
goto err_free;
pd = uobj_get_obj_read(pd, UVERBS_OBJECT_PD, cmd.pd_handle, attrs);
if (!pd) {
ret = -EINVAL;
goto err_free;
}
mr = pd->device->ops.reg_user_mr(pd, cmd.start, cmd.length, cmd.hca_va,
cmd.access_flags,
&attrs->driver_udata);
if (IS_ERR(mr)) {
ret = PTR_ERR(mr);
goto err_put;
}
mr->device = pd->device;
mr->pd = pd;
mr->type = IB_MR_TYPE_USER;
mr->dm = NULL;
mr->sig_attrs = NULL;
mr->uobject = uobj;
atomic_inc(&pd->usecnt);
mr->iova = cmd.hca_va;
rdma_restrack_new(&mr->res, RDMA_RESTRACK_MR);
rdma_restrack_set_name(&mr->res, NULL);
rdma_restrack_add(&mr->res);
uobj->object = mr;
uobj_put_obj_read(pd);
uobj_finalize_uobj_create(uobj, attrs);
resp.lkey = mr->lkey;
resp.rkey = mr->rkey;
resp.mr_handle = uobj->id;
return uverbs_response(attrs, &resp, sizeof(resp));
err_put:
uobj_put_obj_read(pd);
err_free:
uobj_alloc_abort(uobj, attrs);
return ret;
}
5. RXE内核模块中进行实际的Memory Region注册
reg_user_mr 函数的注册
- 由此可知,RXE内核模块中实际上调用了 rxe_reg_user_mr 进行MR的注册
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// kernel/drivers/infiniband/sw/rxe/rxe_verbs.c
static const struct ib_device_ops rxe_dev_ops = {
.owner = THIS_MODULE,
.driver_id = RDMA_DRIVER_RXE,
.uverbs_abi_ver = RXE_UVERBS_ABI_VERSION,
...
.alloc_mr = rxe_alloc_mr,
.alloc_mw = rxe_alloc_mw,
...
.dealloc_mw = rxe_dealloc_mw,
...
.dereg_mr = rxe_dereg_mr,
...
.get_dma_mr = rxe_get_dma_mr,
...
.map_mr_sg = rxe_map_mr_sg,
...
.reg_user_mr = rxe_reg_user_mr,
...
};rxe_reg_user_mr 的实现
- 参数 start/iova 即为 Memory region的起始地址,length 为其长度
rxe_alloc在rxe->mr_pool中申请一个rxe_mr struct 空间- 调用
rxe_mr_init_user, 传入的 mr 结构体指针刚申请空间,无实际内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// kernel/drivers/infiniband/sw/rxe/rxe_verbs.c
static struct ib_mr *rxe_reg_user_mr(struct ib_pd *ibpd,
u64 start,
u64 length,
u64 iova,
int access, struct ib_udata *udata)
{
int err;
struct rxe_dev *rxe = to_rdev(ibpd->device);
struct rxe_pd *pd = to_rpd(ibpd);
struct rxe_mr *mr;
mr = rxe_alloc(&rxe->mr_pool);
if (!mr) {
err = -ENOMEM;
goto err2;
}
rxe_get(pd);
err = rxe_mr_init_user(pd, start, length, iova, access, mr);
if (err)
goto err3;
return &mr->ibmr;
err3:
rxe_put(pd);
rxe_put(mr);
err2:
return ERR_PTR(err);
}rxe_mr_init_user的实现
- 调用 ib_umem_get 来完成内存页面pin操作 + 将pin住的内存页面组织为DMA SG List
- 将 ib_umem 中的DMA SG List复制为 rxe_map_set
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82// kernel/drivers/infiniband/sw/rxe/rxe_mr.c
int rxe_mr_init_user(struct rxe_pd *pd, u64 start, u64 length, u64 iova,
int access, struct rxe_mr *mr)
{
struct rxe_map_set *set;
struct rxe_map **map;
struct rxe_phys_buf *buf = NULL;
struct ib_umem *umem;
struct sg_page_iter sg_iter;
int num_buf;
void *vaddr;
int err;
umem = ib_umem_get(pd->ibpd.device, start, length, access);
if (IS_ERR(umem)) {
pr_warn("%s: Unable to pin memory region err = %d\n",
__func__, (int)PTR_ERR(umem));
err = PTR_ERR(umem);
goto err_out;
}
num_buf = ib_umem_num_pages(umem);
rxe_mr_init(access, mr);
err = rxe_mr_alloc(mr, num_buf, 0);
if (err) {
pr_warn("%s: Unable to allocate memory for map\n",
__func__);
goto err_release_umem;
}
set = mr->cur_map_set;
set->page_shift = PAGE_SHIFT;
set->page_mask = PAGE_SIZE - 1;
num_buf = 0;
map = set->map;
if (length > 0) {
buf = map[0]->buf;
for_each_sgtable_page (&umem->sgt_append.sgt, &sg_iter, 0) {
if (num_buf >= RXE_BUF_PER_MAP) {
map++;
buf = map[0]->buf;
num_buf = 0;
}
vaddr = page_address(sg_page_iter_page(&sg_iter));
if (!vaddr) {
pr_warn("%s: Unable to get virtual address\n",
__func__);
err = -ENOMEM;
goto err_release_umem;
}
buf->addr = (uintptr_t)vaddr;
buf->size = PAGE_SIZE;
num_buf++;
buf++;
}
}
mr->ibmr.pd = &pd->ibpd;
mr->umem = umem;
mr->access = access;
mr->state = RXE_MR_STATE_VALID;
mr->type = IB_MR_TYPE_USER;
set->length = length;
set->iova = iova;
set->va = start;
set->offset = ib_umem_offset(umem);
return 0;
err_release_umem:
ib_umem_release(umem);
err_out:
return err;
}ib_umem_get的实现
- ib_umem 结构体记录传入的起始地址/长度,以及当前用户线程的 mm_struct
- 将 addr 开始的 npages 个页面pin在内存中
pin_user_pages_fast- 将被pin住的n个页面,组织为DMA SG List,保存在 umem ->sgt_append 中
- 调用 sg_alloc_append_table_from_pages 来实现这个目的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123// kernel/drivers/infiniband/core/umem.c
/**
* ib_umem_get - Pin and DMA map userspace memory.
*
* @device: IB device to connect UMEM
* @addr: userspace virtual address to start at
* @size: length of region to pin
* @access: IB_ACCESS_xxx flags for memory being pinned
*/
struct ib_umem *ib_umem_get(struct ib_device *device, unsigned long addr,
size_t size, int access)
{
struct ib_umem *umem;
struct page **page_list;
unsigned long lock_limit;
unsigned long new_pinned;
unsigned long cur_base;
unsigned long dma_attr = 0;
struct mm_struct *mm;
unsigned long npages;
int pinned, ret;
unsigned int gup_flags = FOLL_WRITE;
/*
* If the combination of the addr and size requested for this memory
* region causes an integer overflow, return error.
*/
if (((addr + size) < addr) ||
PAGE_ALIGN(addr + size) < (addr + size))
return ERR_PTR(-EINVAL);
if (!can_do_mlock())
return ERR_PTR(-EPERM);
if (access & IB_ACCESS_ON_DEMAND)
return ERR_PTR(-EOPNOTSUPP);
umem = kzalloc(sizeof(*umem), GFP_KERNEL);
if (!umem)
return ERR_PTR(-ENOMEM);
umem->ibdev = device;
umem->length = size;
umem->address = addr;
/*
* Drivers should call ib_umem_find_best_pgsz() to set the iova
* correctly.
*/
umem->iova = addr;
umem->writable = ib_access_writable(access);
umem->owning_mm = mm = current->mm;
mmgrab(mm);
page_list = (struct page **) __get_free_page(GFP_KERNEL);
if (!page_list) {
ret = -ENOMEM;
goto umem_kfree;
}
npages = ib_umem_num_pages(umem);
if (npages == 0 || npages > UINT_MAX) {
ret = -EINVAL;
goto out;
}
lock_limit = rlimit(RLIMIT_MEMLOCK) >> PAGE_SHIFT;
new_pinned = atomic64_add_return(npages, &mm->pinned_vm);
if (new_pinned > lock_limit && !capable(CAP_IPC_LOCK)) {
atomic64_sub(npages, &mm->pinned_vm);
ret = -ENOMEM;
goto out;
}
cur_base = addr & PAGE_MASK;
if (!umem->writable)
gup_flags |= FOLL_FORCE;
while (npages) {
cond_resched();
pinned = pin_user_pages_fast(cur_base,
min_t(unsigned long, npages,
PAGE_SIZE /
sizeof(struct page *)),
gup_flags | FOLL_LONGTERM, page_list);
if (pinned < 0) {
ret = pinned;
goto umem_release;
}
cur_base += pinned * PAGE_SIZE;
npages -= pinned;
ret = sg_alloc_append_table_from_pages(
&umem->sgt_append, page_list, pinned, 0,
pinned << PAGE_SHIFT, ib_dma_max_seg_size(device),
npages, GFP_KERNEL);
if (ret) {
unpin_user_pages_dirty_lock(page_list, pinned, 0);
goto umem_release;
}
}
if (access & IB_ACCESS_RELAXED_ORDERING)
dma_attr |= DMA_ATTR_WEAK_ORDERING;
ret = ib_dma_map_sgtable_attrs(device, &umem->sgt_append.sgt,
DMA_BIDIRECTIONAL, dma_attr);
if (ret)
goto umem_release;
goto out;
umem_release:
__ib_umem_release(device, umem, 0);
atomic64_sub(ib_umem_num_pages(umem), &mm->pinned_vm);
out:
free_page((unsigned long) page_list);
umem_kfree:
if (ret) {
mmdrop(umem->owning_mm);
kfree(umem);
}
return ret ? ERR_PTR(ret) : umem;
}
6. Kernel 中关于pin memory页面相关流程
整体思路
- 保证N个虚拟地址连续的页面被分配,将每个物理页面的引用计数增大到 GUP_PIN_COUNTING_BIAS
- page->refcount 被置为 GUP_PIN_COUNTING_BIAS 表示该页因为DMA的原因而被PIN住。(bit 10位为1)
入口函数:pin_user_pages_fast
从start开始的虚拟地址,pin住 nr_pages 个数的页面,每个页面的指针保存在 pages 数组中传回
内核相关文档: pin_user_pages() and related calls
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// kernel/mm/gup.c
/**
* pin_user_pages_fast() - pin user pages in memory without taking locks
*
* @start: starting user address
* @nr_pages: number of pages from start to pin
* @gup_flags: flags modifying pin behaviour
* @pages: array that receives pointers to the pages pinned.
* Should be at least nr_pages long.
*
* Nearly the same as get_user_pages_fast(), except that FOLL_PIN is set. See
* get_user_pages_fast() for documentation on the function arguments, because
* the arguments here are identical.
*
* FOLL_PIN means that the pages must be released via unpin_user_page(). Please
* see Documentation/core-api/pin_user_pages.rst for further details.
*/
int pin_user_pages_fast(unsigned long start, int nr_pages,
unsigned int gup_flags, struct page **pages)
{
/* FOLL_GET and FOLL_PIN are mutually exclusive. */
if (WARN_ON_ONCE(gup_flags & FOLL_GET))
return -EINVAL;
if (WARN_ON_ONCE(!pages))
return -EINVAL;
gup_flags |= FOLL_PIN;
return internal_get_user_pages_fast(start, nr_pages, gup_flags, pages);
}
EXPORT_SYMBOL_GPL(pin_user_pages_fast);internal_get_user_pages_fast 函数分析
current->mm->flags增加一个bit: MMF_HAS_PINNED快速路径:页面已经分配出来
模拟TLB miss情况,通过wake page table 最终分析出PTE entry中是否对应物理页,调用过程如下:
1
2
3
4
5
6
7lockless_pages_from_mm
-- gup_pgd_range
-- gup_pud_range
-- gup_pud_range
-- gup_pmd_range
-- gup_pte_range
-- try_grab_folio(page, 1, flags); // 这里会对page refcount + GUP_PIN_COUNTING_BIAS - 1
慢速路径:可能存在一些未建立映射的页面
- __get_user_pages
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47static int internal_get_user_pages_fast(unsigned long start,
unsigned long nr_pages,
unsigned int gup_flags,
struct page **pages)
{
unsigned long len, end;
unsigned long nr_pinned;
int ret;
if (WARN_ON_ONCE(gup_flags & ~(FOLL_WRITE | FOLL_LONGTERM |
FOLL_FORCE | FOLL_PIN | FOLL_GET |
FOLL_FAST_ONLY | FOLL_NOFAULT)))
return -EINVAL;
if (gup_flags & FOLL_PIN)
mm_set_has_pinned_flag(¤t->mm->flags);
if (!(gup_flags & FOLL_FAST_ONLY))
might_lock_read(¤t->mm->mmap_lock);
start = untagged_addr(start) & PAGE_MASK;
len = nr_pages << PAGE_SHIFT;
if (check_add_overflow(start, len, &end))
return 0;
if (unlikely(!access_ok((void __user *)start, len)))
return -EFAULT;
nr_pinned = lockless_pages_from_mm(start, end, gup_flags, pages);
if (nr_pinned == nr_pages || gup_flags & FOLL_FAST_ONLY)
return nr_pinned;
/* Slow path: try to get the remaining pages with get_user_pages */
start += nr_pinned << PAGE_SHIFT;
pages += nr_pinned;
ret = __gup_longterm_unlocked(start, nr_pages - nr_pinned, gup_flags,
pages);
if (ret < 0) {
/*
* The caller has to unpin the pages we already pinned so
* returning -errno is not an option
*/
if (nr_pinned)
return nr_pinned;
return ret;
}
return ret + nr_pinned;
}快速路径:软件模拟TLB走页,把遍历到的每一个页面的page->refcount 增加 GUP_PIN_COUNTING_BIAS - 1
- 五级页表下模拟TLB功能
- 五级页表相关参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48static unsigned long lockless_pages_from_mm(unsigned long start,
unsigned long end,
unsigned int gup_flags,
struct page **pages)
{
unsigned long flags;
int nr_pinned = 0;
unsigned seq;
if (!IS_ENABLED(CONFIG_HAVE_FAST_GUP) ||
!gup_fast_permitted(start, end))
return 0;
if (gup_flags & FOLL_PIN) {
seq = raw_read_seqcount(¤t->mm->write_protect_seq);
if (seq & 1)
return 0;
}
/*
* Disable interrupts. The nested form is used, in order to allow full,
* general purpose use of this routine.
*
* With interrupts disabled, we block page table pages from being freed
* from under us. See struct mmu_table_batch comments in
* include/asm-generic/tlb.h for more details.
*
* We do not adopt an rcu_read_lock() here as we also want to block IPIs
* that come from THPs splitting.
*/
local_irq_save(flags);
gup_pgd_range(start, end, gup_flags, pages, &nr_pinned);
local_irq_restore(flags);
/*
* When pinning pages for DMA there could be a concurrent write protect
* from fork() via copy_page_range(), in this case always fail fast GUP.
*/
if (gup_flags & FOLL_PIN) {
if (read_seqcount_retry(¤t->mm->write_protect_seq, seq)) {
unpin_user_pages_lockless(pages, nr_pinned);
return 0;
} else {
sanity_check_pinned_pages(pages, nr_pinned);
}
}
return nr_pinned;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static void gup_pgd_range(unsigned long addr, unsigned long end,
unsigned int flags, struct page **pages, int *nr)
{
unsigned long next;
pgd_t *pgdp;
pgdp = pgd_offset(current->mm, addr);
do {
pgd_t pgd = READ_ONCE(*pgdp);
next = pgd_addr_end(addr, end);
if (pgd_none(pgd))
return;
if (unlikely(pgd_huge(pgd))) {
if (!gup_huge_pgd(pgd, pgdp, addr, next, flags,
pages, nr))
return;
} else if (unlikely(is_hugepd(__hugepd(pgd_val(pgd))))) {
if (!gup_huge_pd(__hugepd(pgd_val(pgd)), addr,
PGDIR_SHIFT, next, flags, pages, nr))
return;
} else if (!gup_p4d_range(pgdp, pgd, addr, next, flags, pages, nr))
return;
} while (pgdp++, addr = next, addr != end);
}慢速路径:
__get_user_pages:start对应的虚拟地址连续分配nr_pages个物理内存,核心处理思想就是强制显示手动触发page fault流程为其分配物理page,根据其start所属的vma类型处理主要分几种情况处理:
-
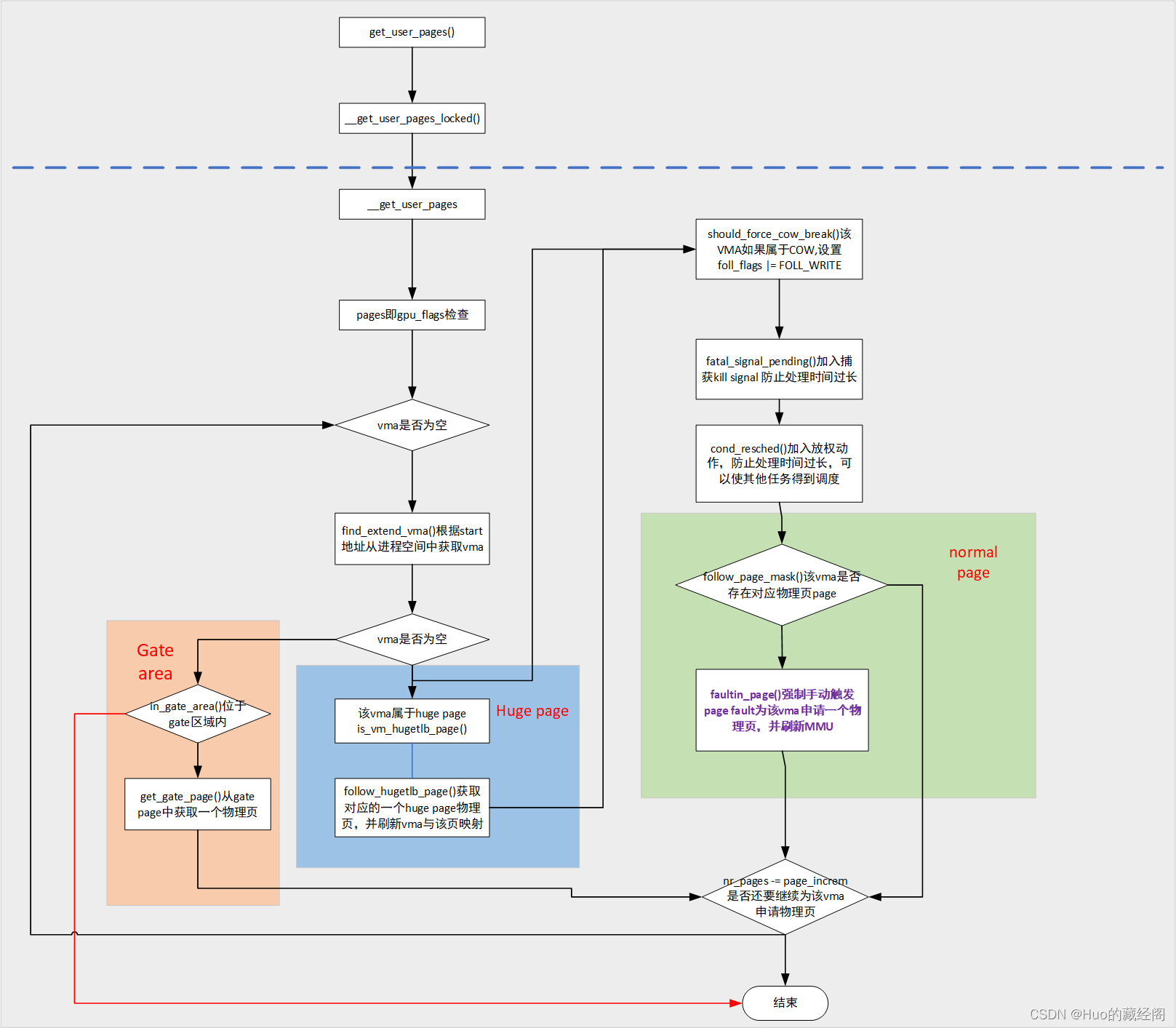
流程讲解:这里参考了 linux那些事之pin memory(get_user_pages())
- __get_user_pages()函数首先调用find_extend_vma()函数查找start所属的vma,find_extend_vma()相比find_vma多了一种功能就是如果查找到的vma不能包括start地址,则可以将vma进行扩展以使查找的vma能够包括start地址。
- 接下来要根据查找到的vma几种情况进行处理:
- vma为空即start地址查找不到对应的所属的vma,且该start地址属于gate are区域则 调用get_gate_page()
- 找到用户空间address对应的struct page。
- 调用try_grab_page对page-> refcount 进行引用计数增加,这里增加了 GUP_PIN_COUNTING_BIAS
- vma为空 也不属于gate area则说明在该进程空间内addr地址还未分配,直接返回。(一般调用__get_user_pages()之前,start所属的vm空间都提前已经申请好)
- vma不为空,且vma属于huge page类型,则触发follow_hugetlb_page()为其申请一个huge page物理页,并刷新MMU
- vma不为空,且vma属于系统默认page大小类型,则调用follow_page_mask()查看page table,查看vma是否分配了物理内存:
- 如果没有分配,则调用faultin_page ()触发page fault流程,为其申请一个物理页
- 如果已经分配物理内存,则直接查看是否需要分配下一页
- vma为空即start地址查找不到对应的所属的vma,且该start地址属于gate are区域则 调用get_gate_page()
- 由于通过page fault流程一次只能分配一个物理页,如果nr_pages需要分配多个物理页,则需要重新循环重新依次进入上面流程。
- 特别需要注意的是,由于触发page fault流程非常耗时,特别是当nr_pages比较大时,整个锁定物理页过程非常耗时。为了在长时间循环中防止各种意外发生,函数调用了fatal_signal_pending()和cond_resched(),分别可以获取KILL signal处理和 cpu放权触发更高优先级任务处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193/**
* __get_user_pages() - pin user pages in memory
* @mm: mm_struct of target mm
* @start: starting user address
* @nr_pages: number of pages from start to pin
* @gup_flags: flags modifying pin behaviour
* @pages: array that receives pointers to the pages pinned.
* Should be at least nr_pages long. Or NULL, if caller
* only intends to ensure the pages are faulted in.
* @vmas: array of pointers to vmas corresponding to each page.
* Or NULL if the caller does not require them.
* @locked: whether we're still with the mmap_lock held
*
* Returns either number of pages pinned (which may be less than the
* number requested), or an error. Details about the return value:
*
* -- If nr_pages is 0, returns 0.
* -- If nr_pages is >0, but no pages were pinned, returns -errno.
* -- If nr_pages is >0, and some pages were pinned, returns the number of
* pages pinned. Again, this may be less than nr_pages.
* -- 0 return value is possible when the fault would need to be retried.
*
* The caller is responsible for releasing returned @pages, via put_page().
*
* @vmas are valid only as long as mmap_lock is held.
*
* Must be called with mmap_lock held. It may be released. See below.
*
* __get_user_pages walks a process's page tables and takes a reference to
* each struct page that each user address corresponds to at a given
* instant. That is, it takes the page that would be accessed if a user
* thread accesses the given user virtual address at that instant.
*
* This does not guarantee that the page exists in the user mappings when
* __get_user_pages returns, and there may even be a completely different
* page there in some cases (eg. if mmapped pagecache has been invalidated
* and subsequently re faulted). However it does guarantee that the page
* won't be freed completely. And mostly callers simply care that the page
* contains data that was valid *at some point in time*. Typically, an IO
* or similar operation cannot guarantee anything stronger anyway because
* locks can't be held over the syscall boundary.
*
* If @gup_flags & FOLL_WRITE == 0, the page must not be written to. If
* the page is written to, set_page_dirty (or set_page_dirty_lock, as
* appropriate) must be called after the page is finished with, and
* before put_page is called.
*
* If @locked != NULL, *@locked will be set to 0 when mmap_lock is
* released by an up_read(). That can happen if @gup_flags does not
* have FOLL_NOWAIT.
*
* A caller using such a combination of @locked and @gup_flags
* must therefore hold the mmap_lock for reading only, and recognize
* when it's been released. Otherwise, it must be held for either
* reading or writing and will not be released.
*
* In most cases, get_user_pages or get_user_pages_fast should be used
* instead of __get_user_pages. __get_user_pages should be used only if
* you need some special @gup_flags.
*/
static long __get_user_pages(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *locked)
{
long ret = 0, i = 0;
struct vm_area_struct *vma = NULL;
struct follow_page_context ctx = { NULL };
if (!nr_pages)
return 0;
start = untagged_addr(start);
VM_BUG_ON(!!pages != !!(gup_flags & (FOLL_GET | FOLL_PIN)));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;
do {
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
/* first iteration or cross vma bound */
if (!vma || start >= vma->vm_end) {
vma = find_extend_vma(mm, start);
if (!vma && in_gate_area(mm, start)) {
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
goto out;
ctx.page_mask = 0;
goto next_page;
}
if (!vma) {
ret = -EFAULT;
goto out;
}
ret = check_vma_flags(vma, gup_flags);
if (ret)
goto out;
if (is_vm_hugetlb_page(vma)) {
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
gup_flags, locked);
if (locked && *locked == 0) {
/*
* We've got a VM_FAULT_RETRY
* and we've lost mmap_lock.
* We must stop here.
*/
BUG_ON(gup_flags & FOLL_NOWAIT);
goto out;
}
continue;
}
}
retry:
/*
* If we have a pending SIGKILL, don't keep faulting pages and
* potentially allocating memory.
*/
if (fatal_signal_pending(current)) {
ret = -EINTR;
goto out;
}
cond_resched();
page = follow_page_mask(vma, start, foll_flags, &ctx);
if (!page || PTR_ERR(page) == -EMLINK) {
ret = faultin_page(vma, start, &foll_flags,
PTR_ERR(page) == -EMLINK, locked);
switch (ret) {
case 0:
goto retry;
case -EBUSY:
ret = 0;
fallthrough;
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
goto out;
}
BUG();
} else if (PTR_ERR(page) == -EEXIST) {
/*
* Proper page table entry exists, but no corresponding
* struct page. If the caller expects **pages to be
* filled in, bail out now, because that can't be done
* for this page.
*/
if (pages) {
ret = PTR_ERR(page);
goto out;
}
goto next_page;
} else if (IS_ERR(page)) {
ret = PTR_ERR(page);
goto out;
}
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start);
flush_dcache_page(page);
ctx.page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
ctx.page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & ctx.page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
out:
if (ctx.pgmap)
put_dev_pagemap(ctx.pgmap);
return i ? i : ret;
}